Home Maria Oelinger
sitemap
Prüfungsprotokoll
Hauptdiplomprüfung Mathematik
Fach: InformationstheoriePrüfer: Prof. Dr. W. Luther, Universität Duisburg
Datum: 29.11.2000
Dauer: ca. 35 Min
Note: 1.0
| Fachgespräch | |||||||||||
| Was stellen Sie sich unter Quellencodierung und Kanalcodierung vor? |
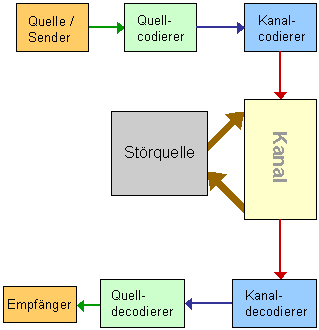
Da fing ich an zu zeichen:
Quellcodierung bedeutet, Daten zu komprimieren.
Kanalcodierung bedeutet, gute Decodierbarkeit zu gewährleisten,
d.h. gute Fehlererkennungs- und Fehlerkorrekturmöglichkeiten. Von der Quelle werden die Informationen (Nachrichten) abgeschickt,
im Quellcodierer komprimiert und vom Kanalcodierer in den Kanal gesandt.
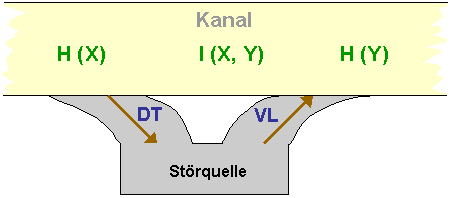
Dort werden sie i.d.R. gestört, d.h. es kommt etwas von außen dazu (Rauschen),
etwas anderes geht verloren.
Der Kanal wird gestört durch eine Störquelle (z.B. Rauschen beim Telefonieren).
|
||||||||||
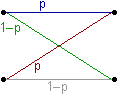
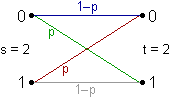
| Welche Arten von Kanälen gibt es? |
|
||||||||||
| Gibt es noch andere Arten von Kanälen? |
Ja: Diskreter gedächtnisloser Kanal DGK mit Inputalphabet S,
Outputalphabet O und Menge von Kanalwahrscheinlichkeiten
p (yj | xi),
wobei
Kanalwahrscheinlichkeiten Beispiel
|
||||||||||
| Woher kommen die gegebenen Wahrscheinlichkeiten? |
Gegeben ist neben der Kanalwahrscheinlichkeit auch die Eingangswahrscheinlichkeit
p (xi).
|
||||||||||
| Welche Wahrscheinlichkeiten interessieren uns noch? |
Die Wahrscheinlichkeit, dass x gesendet wurde, wenn y empfangen ist, nämlich die (rückwärts bedingte) Sendewahrscheinlichkeit p (x | y) = p (x, y) ÷ p (y) (wenn p (y) > 0, sonst p (x | y) = p (x) ) mit der Verbundwahrscheinlichkeit p (x, y) = p (y | x) • p (x)
|
||||||||||
| Wie kann ich wissen, was ich als gesendet annehmen soll? |
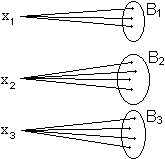
Durch Entscheidungsschemata (partielle Abbildungen)
f: O mit Mengen, für die f für das Output d richtig zum Codewort c hin decodiert: Bc := { d | f (d) = c } = { f –1 (c) } Ideal ist das Schema, wenn gilt: p (f (d) | d) = Maxc Maximum-Likelihood-Entscheidungsschema ist f mit p (d | f (d)) = Maxc Es gilt: Ist die Eingabe gleichverteilt, so ist das MLE-Schema ideal.
|
||||||||||
| Was ist Gleichverteilung? |
Für ein Alphabet S = {x1, …, xs} gilt die Wahrscheinlichkeit p (xi) = 1/s für alle i = 1, ..., s.
|
||||||||||
|
Wo tritt Gleichverteilung in der realen Welt auf? Oder anders: Wie sieht das bei Sprache aus?
|
Ist ganz und gar nicht gleichverteilt.
|
||||||||||
|
Wie sieht das bei Bildern aus?
|
Auch nicht. Kommt drauf an. Schon mehr gleichverteilt als Sprache ;-)
|
||||||||||
| Welche Arten von Codes gibt es? |
variable und Blockcodes
|
||||||||||
| Welche Eigenschaften können sie haben? |
optimal, perfekt, linear, zyklisch, (d – 1)-fehlererkennend, t-fehlerkorrigierend, komplett
|
||||||||||
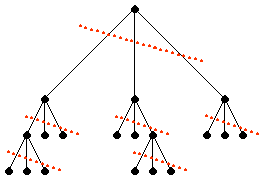
| Was ist ein kompletter Code? |
komplett heißt ein Präfixcode C, wenn für den zugehörigen Codebaum B = (K, P) gilt:
Das Defizit e ist (beim quasikompletten Code) durch
|
||||||||||
| Wie erzeugt man einen Linearcode? |
Mit der Generatormatrix G:
|
||||||||||
|
Wie kann man die Fehlereigenschaften verbessern?
|
z.B. durch Hinzufügen einer Paritätsstelle
|
||||||||||
| Beispiele für Codes? |
Hamming Hq (r), Golay, Huffman
|
||||||||||
|
Wie ist der Minimalabstand bei Hamming-Codes?
|
d = 3 (leicht erkennbar bei Linearcodes wegen wC = d)
|
||||||||||
| Ist das gut? |
Nicht schlecht, aber auch nicht sonderlich gut.
|
||||||||||
|
Wieso ist der Hamming-Code trotzdem so besonders?
|
Er ist perfekt.
|
||||||||||
| Gibt es noch andere perfekte Codes? |
Ja, die beiden Golay-Codes G11 und G23, die haben sogar Mininmalabstände d = 5 und d = 7.
|
||||||||||
Feel free to send me email: maria@oelinger.de
|
© 2000 Maria Oelinger cand. math. |
Prüfungsprotokoll |
Letzte Änderung: 04.12.2000 address: http://www.oelinger.de/maria/it_codi/protokoll_it.htm |