Home Maria Oelinger
sitemap
Prüfungsprotokoll
Hauptdiplomprüfung Mathematik
Fach: CodierungstheoriePrüfer: Prof. Dr. G. Törner, Universität Duisburg
Datum: Nov 2000
Dauer: ca. 25 Min
Note: 1.3
| Fragenkatalog | ||
| Was ist die Codierung allgemein, wozu dient sie, wozu nicht? |
Man möchte Daten übertragen,
also an einem Ort möglichst einfach und originalgetreu rekonstruieren können,
was an einem andern Ort ausgewählt und gesendet wurde.
|
|
| Inwiefern möchte man Codes optimieren? |
Sie sollen möglichst kurze Übertragungszeit bzw. Speicherplatz beanspruchen. Außerdem sollen sie einfach zu codieren sein und fehlertolerant.
|
|
| Welche Codes kennen Sie überhaupt? |
Präfixcodes zum Beispiel, Huffman-Codes…
|
|
| Welchen Präfixcode kennen Sie denn? |
Der Huffman-Code ist ein Präfixcode.
|
|
| Kennen Sie noch mehr? Aus dem täglichen Leben? |
Telefonnummern!
|
|
| Geben Sie ein allgemeines Modell an! |
Die Nachricht (x1, …, xk) wird codiert
und zum Codewort (y1, …, yn), wobei n > k,
da z.B. Prüfziffern hinzukommen.
Dieses Wort schicke ich durch einen Kanal (z.B. Telefonleitung).
|
|
| Das führt zu einem speziellen Code, welcher ist das? |
Ein Blockcode, genauer: (n, k)-Blockcode. Das ist ein Quadrupel (X, Y, E, D) mit nichtleeren Mengen X und Y (die heißen Alphabete) und Abbildungen E: Xk D: Yn Wieviele Elemente haben die Alphabete? In der Praxis endlich viele. Wieviele Elemente haben sie denn meistens? Zwei (Binärcodes).
|
|
| Welche Aussagen kann man machen, wenn man die Werte des (n, k)-Blcokcodes kennt? |
Man kann die Informationsrate k/n bzw. 1/n • log q M angeben, die ein Maß dafür ist, wieviel Information durch den Code vermittelt werden kann. Je näher sie bei 1 liegt, desto mehr Information kommt rüber.
|
|
| Was spricht gegen eine hohe Informationsrate? |
Die Fehleranfälligkeit,
d.h. der Unterschied zwischen den einzelnen Codewörtern ist dann sehr gering,
so dass durch gestörte Übertragung aufgetretene Fehler nicht erkannt werden können.
Das kann man durch den Minimalabstand beschreiben:
|
|
| Jetzt kommt die Frage nach optimalen und perfekten Codes. |
Dazu eine weitere Definition: Für den perfekten Code betrachtet man die Kugelpackungsschranke:
Erreicht ein Code diese Schranke (d.h. Gleichheit), so heißt er perfekt. Welche perfekten Codes kennen Sie? Golay G23 und G11 und den Hamming-Code. Kennen Sie noch mehr? Nein, man kennt nur diese. Können Sie die Schranke näher erläutern?
Also enthält jede Kugel genau
|
|
| Welche Arten von Codes gibt es noch? |
Ein Linearcode bildet einen Unterraum des Vektorraums
GF (q)n. Es sind [n, k, d; q]-Codes mit Wortlänge n,
Dimension bzw. Anzahl der Informationsstellen (wie im Modell ganz oben) k,
dem Minimalabstand d und einem q-nären Alphabet. Wie beschreibt man einen solchen Code hinreichend? Wie sieht dann der Code aus?
C = { x
|
|
| Gibt es überhaupt lineare Codes, die optimale sind? |
Ja, den Hamming-Code. Er wird auf verschiedene Arten definiert,
z. B. über den Minimalabstand.
|
|
| Es gibt noch eine andere Klasse von Codes. Welche? |
Die zyklischen Codes. Dabei erzeugt ein Wort, z.B. 10110, den Code, indem ich es shifte, d.h. dass 01011 und alle andern Shifts wieder Codewörter sind. Die Generatormatrix dazu ist
wobei man Codewörter auch als Polynome verstehen kann: Wie sieht denn der Shift für das Codewort aus? Beschreiben Sie den Code explizit!
|
|
| Sagen Sie etwas über Prüfzeichencodes. Nur allgemein und ein Beispiel. |
Man benutzt Permutationen, die, angewandt auf die Koordinaten meines Wortes,
eine Kontrollgleichung erfüllen sollen.
z.B. ISBN-Code mit der Kontrollgleichung
a10 Machen Sie die Gleichung homogen. Was ist denn der zugrundeliegende Körper? GF (q). Wie sieht die Kontrollmatrix aus?
|
|
| Nochmal zu den Schranken: Kennen Sie noch andere als die Kugelpackungsschranke? |
Klar, die Singleton-Schranke: Die Plotkin-Schranke: Für q = 2: A (n, d; q) Und die untere Schranken (bisher waren es ja ausschließlich obere Schranken) von
Gilbert-Varshamov: die der Kugelpackungsschranke ähnlich ist, außer dass sie in der Summe bis d – 1 geht, das ist die Anzahl der Fehler, die ich erkennen kann.
|
|
| Schließlich noch etwas zu Code-Modifikationen |
Erweitern Punktieren Vergrößern Verkleinern Verlängern Verkürzen
|
|


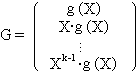
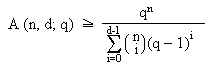
Feel free to send me email: maria@oelinger.de
|
© 2000 Maria Oelinger cand. math. |
Prüfungsprotokoll |
Letzte Änderung: 04.12.2000 address: http://www.oelinger.de/maria/it_codi/protokoll_it.htm |